Tree
Tree는 node와 edge로 이루어진 계층형 자료구조다. Graph 관점에서 보면 connected acyclic graph, 즉 모든 node가 연결되어 있고 cycle이 없는 graph다.
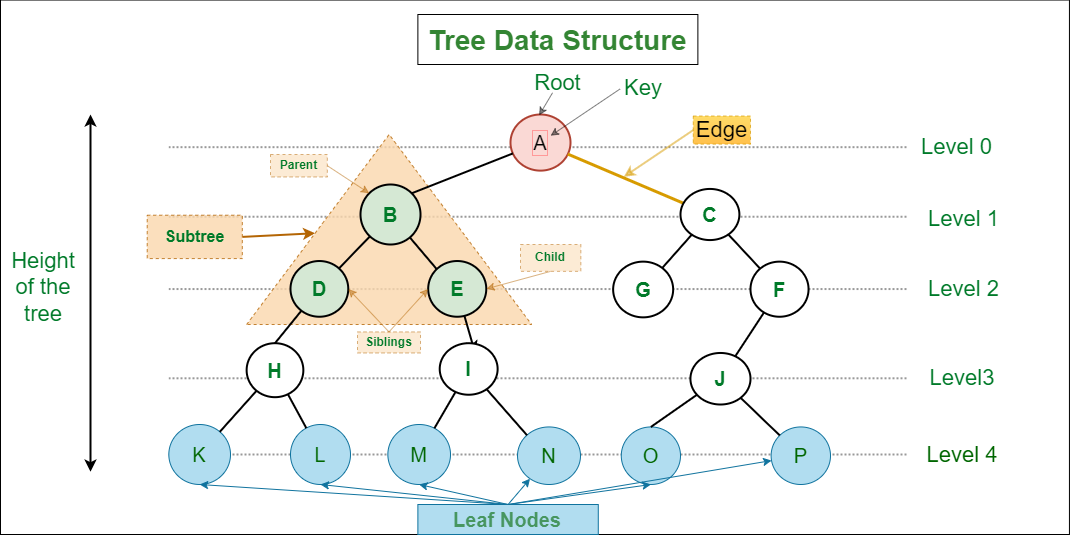 source: https://www.geeksforgeeks.org/introduction-to-tree-data-structure-and-algorithm-tutorials/
source: https://www.geeksforgeeks.org/introduction-to-tree-data-structure-and-algorithm-tutorials/
핵심 성질
Tree를 이해할 때 가장 중요한 성질은 아래 3개다.
- node가
n개인 tree는 edge가n - 1개다. - 임의의 두 node 사이에는 path가 정확히 하나만 존재한다.
- edge를 하나 추가하면 cycle이 생기고, edge를 하나 제거하면 연결이 끊어진다.
보통 프로그래밍에서 말하는 tree는 root가 있는 rooted tree다. Root를 기준으로 parent-child 관계가 생기고, root에서 멀어질수록 depth가 깊어진다.
용어
| 용어 | 의미 |
|---|---|
| Root | 부모가 없는 시작 node |
| Parent | 어떤 node 바로 위에 있는 node |
| Child | 어떤 node 바로 아래에 있는 node |
| Sibling | 같은 parent를 가진 node |
| Leaf | child가 없는 node |
| Internal node | leaf가 아닌 node |
| Degree | child 개수 |
| Depth | root에서 해당 node까지 edge 개수 |
| Height | 해당 node에서 가장 먼 leaf까지 edge 개수 |
| Subtree | 어떤 node를 root로 하는 부분 tree |
예를 들어 root의 depth는 0이고, leaf의 height는 0이다. 문제마다 height를 edge 개수
대신 node 개수로 정의하는 경우도 있으니 면접이나 알고리즘 문제에서는 정의를 먼저 확인하는
게 좋다.
Tree 종류
Binary Tree
각 node가 최대 2개의 child를 가지는 tree다. 보통 child를 left, right로 부른다.
Binary Search Tree
Binary tree에 ordering rule을 추가한 tree다.
left subtree의 모든 값 < root 값 < right subtree의 모든 값이 규칙 덕분에 search, insert, delete가 평균적으로 O(log n)이 될 수 있다. 하지만 tree가
한쪽으로 기울면 height가 n이 되어 O(n)까지 나빠진다.
Self-balancing Search Tree
Insert/delete 이후 height가 너무 커지지 않도록 스스로 균형을 맞추는 search tree다.
- AVL tree
- Red-black tree
- B-tree
여기서 주의할 점: B-tree는 binary tree가 아니다. 하나의 node가 여러 key와 여러 child를 가질 수 있는 multi-way balanced search tree다. Database index나 filesystem에서 자주 등장한다.
Full / Complete / Perfect Binary Tree
이 세 용어는 이름이 비슷해서 자주 헷갈린다.
| 종류 | 조건 |
|---|---|
| Full binary tree | 모든 node의 child 개수가 0개 또는 2개다 |
| Complete binary tree | 마지막 level을 제외한 모든 level이 꽉 차 있고, 마지막 level은 왼쪽부터 채워져 있다 |
| Perfect binary tree | 모든 internal node가 child 2개를 가지고, 모든 leaf가 같은 depth에 있다 |
Perfect binary tree는 항상 full이면서 complete다. 하지만 full이라고 해서 complete인 것은 아니고, complete라고 해서 full인 것도 아니다.
Traversal
Traversal은 tree의 모든 node를 한 번씩 방문하는 방법이다. Tree node가 n개라면 모든
traversal은 기본적으로 O(n)이다.
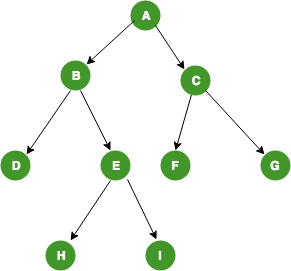
DFS: Depth-First Search
DFS는 한 방향으로 끝까지 내려갔다가 다시 돌아오는 방식이다. Recursive call stack을 쓰거나 직접 stack을 만들어 구현한다.
Binary tree에서 DFS 순회는 root를 언제 방문하느냐에 따라 이름이 달라진다.
| 순회 | 순서 | 예시 |
|---|---|---|
| Preorder | Root -> Left -> Right | A-B-D-E-H-I-C-F-G |
| Inorder | Left -> Root -> Right | D-B-H-E-I-A-F-C-G |
| Postorder | Left -> Right -> Root | D-H-I-E-B-F-G-C-A |
외우는 법은 간단하다. Left는 항상 Right보다 먼저 간다. Root가 앞이면 preorder, 중간이면 inorder, 뒤면 postorder다.
Inorder traversal은 binary search tree에서 특히 중요하다. BST를 inorder로 순회하면 값이 정렬된 순서로 나온다.
fn inorder(node: Option<&Box<TreeNode>>, output: &mut Vec<i32>) {
if let Some(node) = node {
inorder(node.left.as_ref(), output);
output.push(node.val);
inorder(node.right.as_ref(), output);
}
}DFS의 extra space는 tree height를 h라고 할 때 recursive call stack 기준 O(h)다.
Balanced tree라면 O(log n), 한쪽으로 기운 tree라면 O(n)이다.
BFS: Breadth-First Search
BFS는 level order traversal이라고도 부른다. Root에서 시작해 같은 depth의 node를 먼저 방문한 뒤 다음 level로 내려간다.
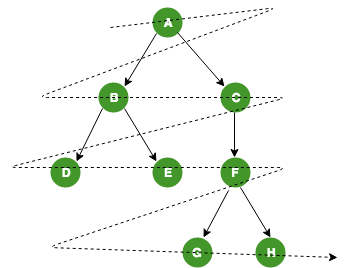
BFS는 queue로 구현한다. Tree의 level별 처리, 최단 edge 수 계산, serialization 문제에서 자주 등장한다.
use std::collections::VecDeque;
fn level_order(root: Option<&Box<TreeNode>>) -> Vec<i32> {
let mut result = Vec::new();
let mut queue = VecDeque::new();
if let Some(root) = root {
queue.push_back(root);
}
while let Some(node) = queue.pop_front() {
result.push(node.val);
if let Some(left) = node.left.as_ref() {
queue.push_back(left);
}
if let Some(right) = node.right.as_ref() {
queue.push_back(right);
}
}
result
}BFS의 extra space는 queue에 들어가는 최대 node 수에 비례한다. Tree의 최대 width를 w라고
하면 O(w)다. Complete binary tree의 마지막 level은 node가 많기 때문에 최악의 경우
O(n)이 될 수 있다.
표현 방법
Linked node
가장 일반적인 표현 방식이다. 각 node가 자기 child를 가리킨다.
#[derive(Debug)]
pub struct TreeNode {
pub val: i32,
pub left: Option<Box<TreeNode>>,
pub right: Option<Box<TreeNode>>,
}
impl TreeNode {
pub fn new(val: i32) -> Self {
Self {
val,
left: None,
right: None,
}
}
}LeetCode의 Rust tree 문제에서는 공유 ownership과 interior mutability 때문에
Option<Rc<RefCell<TreeNode>>> 형태를 자주 본다. 하지만 tree 개념 자체를 설명할 때는
Box<TreeNode>가 더 단순하다.
Array
Complete binary tree처럼 빈 공간이 거의 없는 tree는 array로 표현하기 좋다.
Root index를 0이라고 하면:
left child = 2 * i + 1
right child = 2 * i + 2
parent = (i - 1) / 2Heap이 이 표현을 사용한다.
struct ArrayTree {
nodes: Vec<Option<i32>>,
}
impl ArrayTree {
fn left_index(parent: usize) -> usize {
2 * parent + 1
}
fn right_index(parent: usize) -> usize {
2 * parent + 2
}
}Array 표현은 index 계산이 빠르고 cache locality가 좋다. 하지만 sparse tree에는 빈 칸이 많아져 memory가 낭비된다.
Complexity
| 작업 | 일반 binary tree | balanced BST | 한쪽으로 기운 BST |
|---|---|---|---|
| Search | O(n) | O(log n) | O(n) |
| Insert | O(n) 또는 위치를 알면 O(1) | O(log n) | O(n) |
| Delete | O(n) | O(log n) | O(n) |
| Traversal | O(n) | O(n) | O(n) |
Tree 문제에서 중요한 것은 "binary tree인가, BST인가, balanced인가"를 먼저 구분하는 것이다. 셋을 섞어서 생각하면 time complexity를 쉽게 틀린다.
어디에 쓰나
- File system directory 구조
- HTML/XML DOM
- Compiler AST(Abstract Syntax Tree)
- Database index(B-tree, B+tree)
- Priority queue(heap)
- Prefix search(trie)
- Range query(segment tree, Fenwick tree)
기억할 점
- Tree는 cycle이 없는 connected graph다.
- Rooted tree에서는 parent-child 관계가 생긴다.
- Binary tree와 binary search tree는 다르다.
- Balanced BST는 height를 낮게 유지해서 search/insert/delete를
O(log n)에 가깝게 만든다. - BFS는 queue, DFS는 stack 또는 recursion으로 구현한다.
- Array tree 표현은 complete binary tree나 heap에 잘 맞고, sparse tree에는 비효율적이다.
Ref
- Tree data structure: https://en.wikipedia.org/wiki/Tree_(data_structure)
- Binary tree: https://en.wikipedia.org/wiki/Binary_tree
- Binary search tree: https://en.wikipedia.org/wiki/Binary_search_tree
- Self-balancing binary search tree: https://en.wikipedia.org/wiki/Self-balancing_binary_search_tree
- B-tree: https://en.wikipedia.org/wiki/B-tree
- Binary heap: https://en.wikipedia.org/wiki/Binary_heap
- CP-Algorithms - Segment Tree: https://cp-algorithms.com/data_structures/segment_tree.html
- GeeksforGeeks - Binary tree array implementation: https://www.geeksforgeeks.org/binary-tree-array-implementation/